Using ML-Backed Transcription to Quickly Edit Flight Sim Videos
Scroll DownAs I pitched in an earlier post, making non-flyers feel like they’re up there with you, experiencing the engaging parts of the flying experience - combat or civil - is the low-expense, high-yield way to help drive more community engagement into the world of flight sims.
The key medium for doing this is video. All bells and whistles - from chat to “choose your own adventure” Twitch-Plays-Pokemon style remote flight stuff - ultimately have video at the base.
And, flying is 90% going in a straight line looking at instruments. Look, I’m one of those weirdos that sees it as a feature, not a bug - I get an odd mix of thrill and calm out of babysitting my engines (and I have some ideas about making that 90% more instructive and dramatic, we’ll talk later) - but in general that 90% doesn’t make great TV. The interesting 10% can.
Editing for interest, a 90-minute flight session can end up between 5 and 20 minutes of interesting bits strung together with some kind of narrative. Creating that narrative - and seeking, assembling, and producing the interesting string of clips - takes forever.
I’m not exaggerating - let’s look at some math.
Let’s assume a 4 minute video is made of fifteen 16-second clips that contain spoken tracks with some padding around the start and end. It’s not likely spoken phrases are longer than 8 seconds (try talking for 8 seconds), so if you add 4 seconds to the start and the end, you get 16 seconds.
The question:
Let’s say we need to “seek” fifteen clips. How long will that take?
- The trick if you don’t have a transcript is you don’t know where the speaking starts and ends unless you go scrubbing for it.
- That means you’ll have to watch at least the entire video.
- So it’ll take at least an hour to seek fifteen clips in a one hour video.
-
This doesn’t account for mistakes. If every seek has two minutes of messing around, that’s another 30 minutes total.
The equation is SOURCE TIME + (2 MIN * NUMBER OF CLIPS) Seeking 15 clips from a 60 min video = (60 + 30) = 90min Seeking 15 clips from a 90 min video = (90 + 30) = 120min Seeking 20 clips from a 90 min video = (90 + 40) = 130min
This isn’t just hypothetical. Here - take a look at this supercut of a 100-minute flight session I did with my wingman and AWACS:
That took 2 hours and 30 minutes – a total of 150 minutes – to cut that down, with no other editing or post-production. It was about 30 clips worth. Pretty darn close to my napkin math up there.
The majority of time was finding the interesting parts, and lining up to the start and end of relevant dialogue.
I already spent 100 minutes flying. Am I going to spend that plus half again on just cutting up my video?
There’s gotta be a better way.
Enter ML Transcription
Here’s the thing. We already know there’s a ton of non-interesting stuff going on while flying. Where’s the interesting stuff usually at? Takeoff, landing, we know that one.
But it’s also when we’re speaking.
Instructing, talking on the radio, talking to the audience, yelling in the heat of combat - talking is where the story gets told. If we look for the words and cut at those beats, we’ll get the narrative.
What if we can get at the words quicker?
Enter machine-learning backed transcription. For this test I used Amazon Transcribe, a feature of Amazon Web Services, which I’m already using to host this site. You can read all about it, the short version is you hand it a video or audio track, you get back a transcript with a heap of metadata that you can ingest into whatever it is you need it for.
For my purposes, what I want is a transcript lined up with video timecodes. If I can tie a timecode to the start and end of relevant pieces of dialogue, I can scrub to those timecodes very quickly – maybe even automatically using scripting – and set my In/Out markers for clip assembly.
I gave it a try, and timed it out as a comparison.
Here’s a different 100-minute video that I fed into the transcription engine, using the timecodes it spit back as a way to set In/Out clip markers.
This took only about 70 minutes - close to just half as much time as without transcription.
A lot of that time can still be made more efficient, because as a first try, I fumbled a lot. Here’s what I learned; these tips might help you go faster:
 ML Transcription by AWS Transcribe - an Example of my Flight Transcript
ML Transcription by AWS Transcribe - an Example of my Flight Transcript
- It costs. About $1.50 to transcribe an hour long video. Here’s the pricing sheet.
- It will only read from an AWS S3 bucket. So you have to use S3.
- It won’t work on anything > 2GB. So don’t send it the video, chop out the audio track and send that. Smaller, faster.
- Audio formats allowed are mp3, mp4, wav, and flac.
- It can try to identify speakers or it can identify channels (left, right). If you’ve got your radio output set to just one ear, it can identify that.
- Confidence levels can waver on short words, but I was surprised to get the high confidence %s I got given the prop noise. The background sound didn’t seem to have a negative effect, but I haven’t compared to a “clean” sample.
- The quickest way to get timecodes is to use their preview window (shown in the image above) and hover over the words you’re interested in. However, that preview caps at 5000 words. Any more and you need the full transcript in JSON.
- And that JSON is ugly. The timecodes and every single word spoken are stored separately, tying them back together into a cognitively-recognizable format requires a data transformation.
- However - this utility from kibaffo33 on GitHub does a great job outputting that JSON format to a Microsoft Word file with some neat stats as well. Note that it appears to need speaker identification turned ON in the transcript to work correctly, but the output is impressive:
 Output from AWS_Transcribe_To_Docx - Much better!
Output from AWS_Transcribe_To_Docx - Much better!
How It Went
Here are two versions of a video that’s been auto-cut from a 40-minute original, by my automation workflow.
The first takes every 2-second or longer speech clip, stringing them together with no buffer.
Here’s the second - still 2-second minimum, but a one-second buffer at the end of each segment.
Clearly - we’ve got some issues.
- Speech is interesting - but it’s not the only interesting thing. The algorithm fails to capture carrier launch and landing, missile shots, dogfights.
- Buffering the ends is problematic. Without it, cuts are jarring and some end early. With it, you’ll sometimes get duplications of speech.
How it Works:
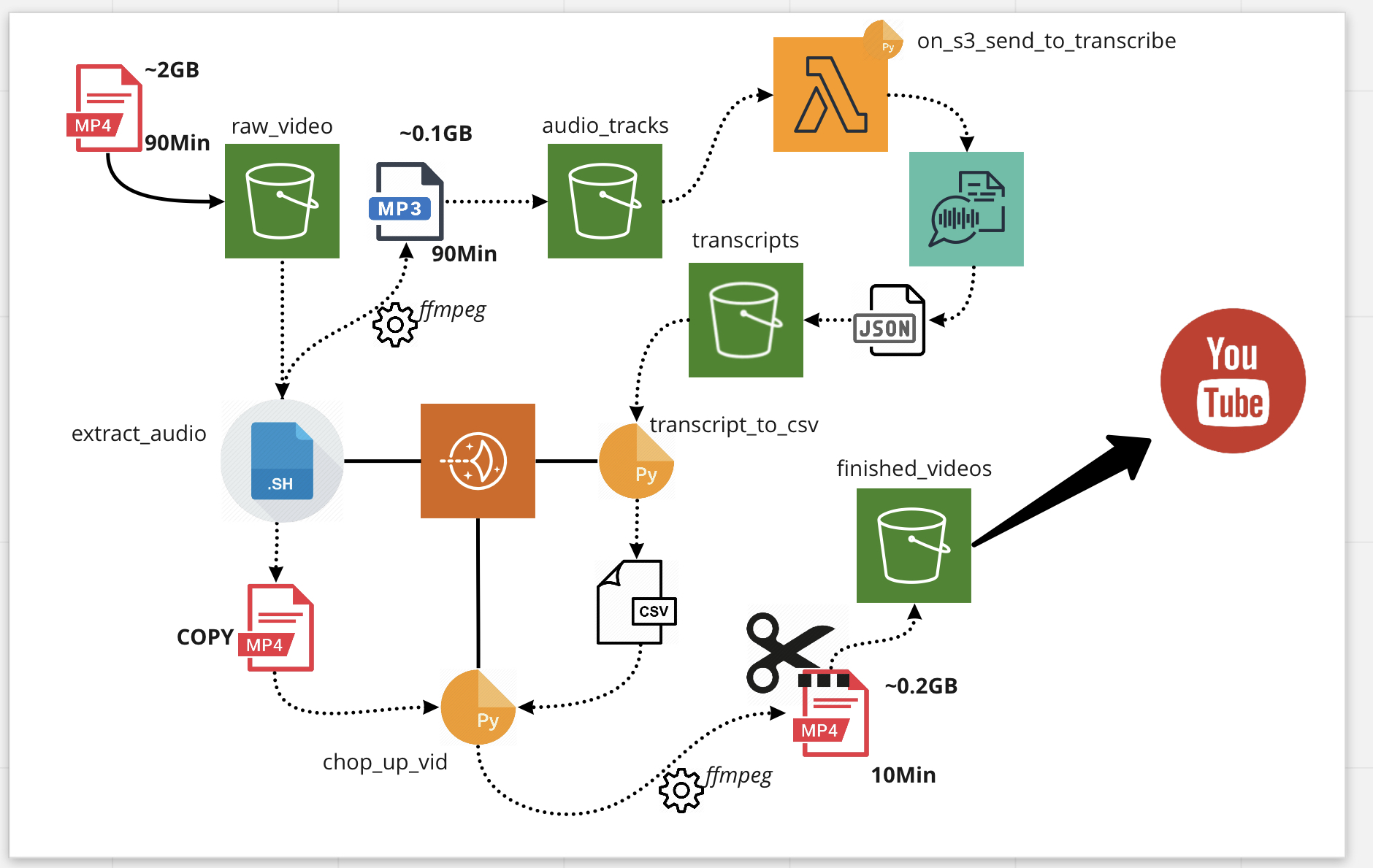 The ML Transcription Workflow - Bash, Python, S3, Amazon Transcribe, Lightsail and Lambda
The ML Transcription Workflow - Bash, Python, S3, Amazon Transcribe, Lightsail and Lambda
The overall workflow is several small scripts that each take a single step in the flow, each operating on a collection of files in different S3 buckets or folders. The processed files go to the next bucket where the following operation will find them.
- Most of the compute is done on a Lightsail instance (EC2), loaded with Python3.7, the AWS CLI, and a command-line audio and video processor called ffmpeg.
- There’s one Lambda function (serverless compute) that watches one of the S3 buckets and hands off MP3 files to AWS Transcribe.
- It probably makes sense to convert most of the compute functions into Lambdas as well - the Lightsail instance also runs my website and doesn’t need to be overloaded by video processing and AWS I/O.
The Code So Far:
I’ve made a couple parts of the code available on GitHub at https://github.com/agentcox/mlvidchopper:
- Python script that converts Amazon Transcribe JSON to CSV - adapted from kibaffo33’s JSON to DOCX converter.
- Python script that pulls in the CSV from above and creates a shell script to automate the cutting up of the video based on transcript timecodes.